JVM 原理
JVM简介
1
2
3JVM是虚拟机,也是一种规范,他遵循着冯·诺依曼体系结构的设计原理(冯·诺依曼体系结构中,指出计算机处理的数据和指令都是二进制数,采用存储程序方式不加区分的存储在同一个存储器里,并且顺序执行,指令由操作码和地址码组成,操作码决定了操作类型和所操作的数的数字类型,地址码则指出地址码和操作数).
从DOS到window8,从unix到ubuntu和CentOS,还有MAC OS等等,不同的操作系统指令集以及数据结构都有着差异,而JVM通过在操作系统上建立虚拟机,自己定义出来的一套统一的数据结构和操作指令,把同一套语言翻译给各大主流的操作系统,实现了跨平台运行,可以说JVM是Java的核心,是java可以一次编译到处运行的本质所在.JVM的组成和运行原理
1
2
3
4
5JVM的毕竟是个虚拟机,是一种规范,虽说符合冯诺依曼的计算机设计理念,但是他并不是实体计算机,所以他的组成也不是什么存储器,控制器,运算器,输入输出设备.
在我看来,JVM放在运行在真实的操作系统中表现的更像应用或者说是进程,他的组成可以理解为JVM这个进程有哪些功能模块,而这些功能模块的运作可以看做是JVM的运行原理.
JVM有多种实现,例如: Oracle的JVM,HP的JVM和IBM的JVM等,而在本文中研究学习的则是使用最广泛的Oracle的HotSpot JVM.JVM在JDK中的位置
1
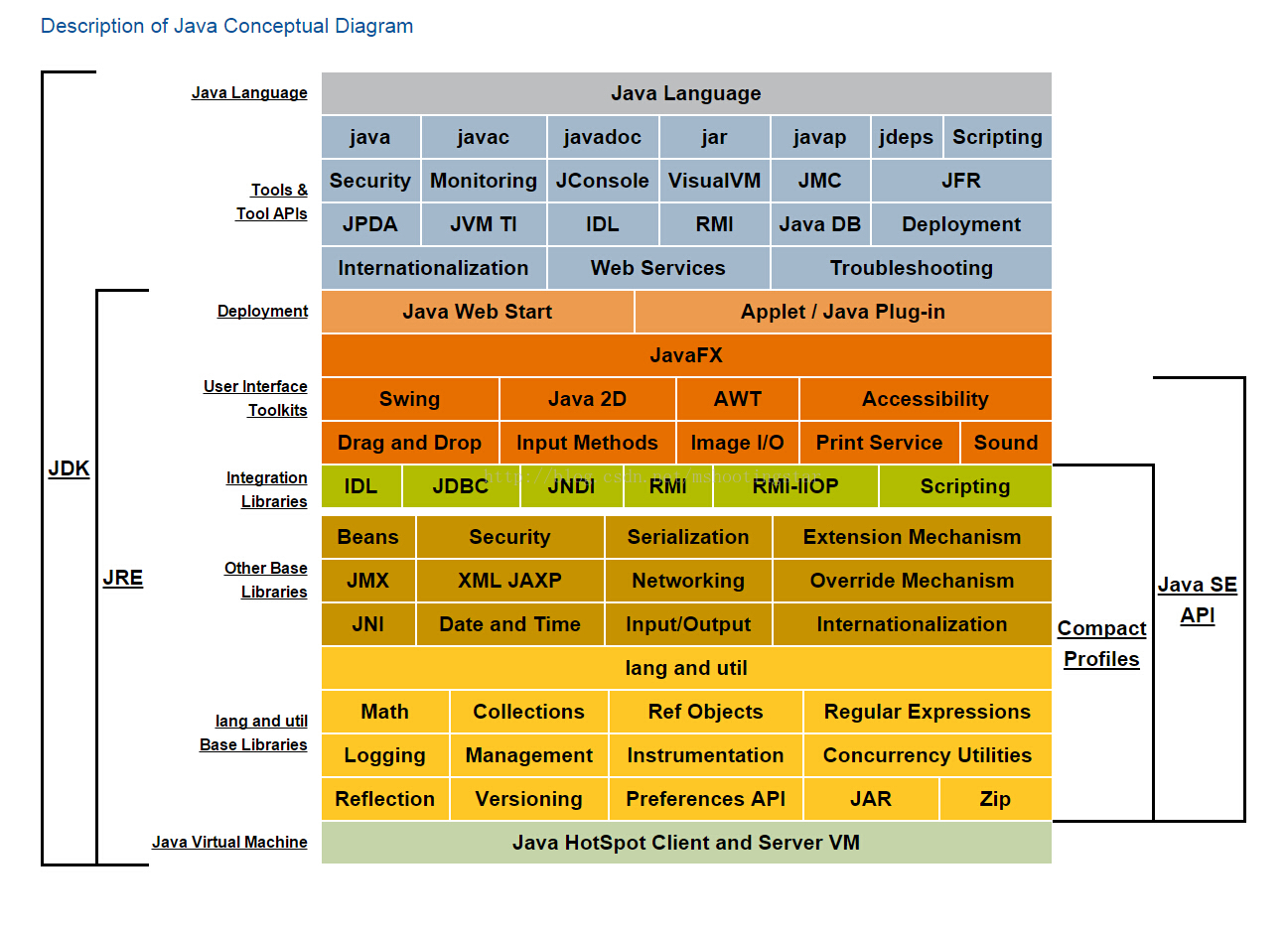
2JDK是Java开发的必备工具箱,JDK其中有一部分是JRE,JRE是JAVA运行环境,JVM则是JRE最核心的部分.
如图:JDK Standard Edtion
1
2
3
4
5
6
7
8
9
10
11
12
13从最底层的位置可以看出来JVM有多重要,而实际项目中JAVA应用的性能优化,OOM等异常的处理最终都得从JVM这儿来解决
HotSpot是Oracle关于JVM的商标,区别于IBM,HP等厂商开发的JVM
Java HotSpot Client VM和Java HotSpot Server VM是JDK关于JVM的两种不同的实现,前者可以减少启动时间和内存占用,而后者则提供更加优秀的程序运行速度
例如:
[root@10 ~]# java -version
java version "1.8.0_73"
Java(TM) SE Runtime Environment (build 1.8.0_73-b02)
Java HotSpot(TM) 64-Bit Server VM (build 25.73-b02, mixed mode)
HotSpot的版本号是25.73-b02,类型是Java HotSpot Server VM
- JVM的组成
1
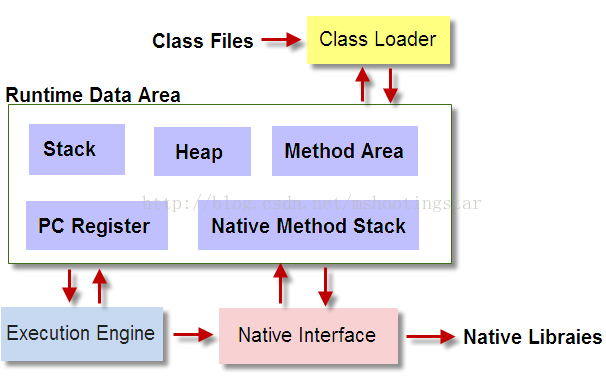
JVM由4大部分组成: ClassLoader,Runtime Data Area,Execution Engine,Native Interface
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35JVM组成部分说明:
* ClassLoader
ClassLoader是负责加载class文件,class文件在文件开头有特定的文件标示,并且ClassLoader只负责class文件的加载,至于它是否可以运行,则由Execution Engine决定
* Native Interface
Native Interface是负责调用本地接口的.它的作用是调用不同语言的接口给JAVA用,他会在Native Method Stack中记录对应的本地方法,然后调用该方法时就通过Execution Engine加载对应的本地lib
* Execution Engine
Execution Engine是执行引擎,也叫Interpreter.Class文件被加载后,会把指令和数据信息放入内存中,Execution Engine则负责把这些命令解释给操作系统
* Runtime Data Area
Runtime Data Area则是存放数据的,分为五部分:Stack,Heap,Method Area,PC Register,Native Method Stack.几乎所有的关于java内存方面的问题,都是集中在这块
* Stack
Stack是java栈内存,它等价于C语言中的栈,栈的内存地址是不连续的,每个线程都拥有自己的栈.
栈里面存储着的是StackFrame,在《JVM Specification》中文版中被译作java虚拟机框架,也叫做栈帧.
StackFrame包含三类信息: 局部变量,执行环境,操作数栈
* 局部变量用来存储一个类的方法中所用到的局部变量
* 执行环境用于保存解析器对于java字节码进行解释过程中需要的信息,包括:上次调用的方法,局部变量指针和操作数栈的栈顶和栈底指针
* 操作数栈用于存储运算所需要的操作数和结果
StackFrame在方法被调用时创建,在某个线程中,某个时间点上,只有一个框架是活跃的,该框架被称为Current Frame,而框架中的方法被称为Current Method,其中定义的类为Current Class.局部变量和操作数栈上的操作总是引用当前框架.当Stack Frame中方法被执行完之后,或者调用别的StackFrame中的方法时,则当前栈变为另外一个StackFrame.Stack的大小是由两种类型:固定和动态的,动态类型的栈可以按照线程的需要分配
* Heap
Heap是用来存放对象信息的,和Stack不同,Stack代表着一种运行时的状态.换句话说,栈是运行时单位,解决程序该如何执行的问题,而堆是存储的单位,解决数据存储的问题.
Heap是伴随着JVM的启动而创建,负责存储所有对象实例和数组的.堆的存储空间和栈一样是不需要连续的,它分为Young Generation和Old Generation(也叫Tenured Generation)两大部分.Young Generation分为Eden和Survivor,Survivor又分为From Space和 ToSpace.
和Heap经常一起提及的概念是PermanentSpace,它是用来加载类对象的专门的内存区,是非堆内存,和Heap一起组成JAVA内存,它包含MethodArea区(在没有CodeCache的HotSpotJVM实现里,则MethodArea就相当于GenerationSpace)
在JVM初始化的时候,我们可以通过参数来分别指定,PermanentSpace的大小,堆的大小,以及Young Generation和Old Generation的比值,Eden区和From Space的比值,从而来细粒度的适应不同JAVA应用的内存需求
* PC Register
PC Register是程序计数寄存器,每个JAVA线程都有一个单独的PC Register,他是一个指针,由Execution Engine读取下一条指令.如果该线程正在执行java方法,则PC Register存储的是正在被执行的指令的地址;如果是本地方法,PC Register的值没有定义.PC寄存器非常小,只占用一个字宽,可以持有一个returnAdress或者特定平台的一个指针
* Method Area
Method Area在HotSpot JVM的实现中属于非堆区,非堆区包括两部分:Permanet Generation和Code Cache,而Method Area属于Permanert Generation的一部分.
Permanent Generation用来存储类信息,比如说:class definitions,structures,methods,field,method(data and code)和constants.
Code Cache用来存储Compiled Code,即编译好的本地代码,在HotSpot JVM中通过JIT(Just In Time)Compiler生成,JIT是即时编译器,他是为了提高指令的执行效率,把字节码文件编译成本地机器代码
* Native Method Stack
Native Method Stack是供本地方法(非java)使用的栈.每个线程持有一个Native Method Stack
JVM的运行原理简介
1
2
3
4Java程序被javac工具编译为.class字节码文件之后,我们执行java命令,该class文件便被JVM的Class Loader加载,可以看出JVM的启动是通过JAVA Path下的java.exe或者java进行的.
JVM的初始化,运行到结束大概包括这么几步:
调用操作系统API判断系统的CPU架构,根据对应CPU类型寻找位于JRE目录下的/lib/jvm.cfg文件,然后通过该配置文件找到对应的jvm.dll文件(如果我们参数中有-server或者-client,则加载对应参数所指定的jvm.dll,启动指定类型的JVM),初始化jvm.dll并且挂接到JNIENV结构的实例上,之后就可以通过JNIENV实例装载并且处理class文件了.class文件是字节码文件,它按照JVM的规范,定义了变量,方法等的详细信息,JVM管理并且分配对应的内存来执行程序,同时管理垃圾回收.直到程序结束,一种情况是JVM的所有非守护线程停止,一种情况是程序调用System.exit(),JVM的生命周期也结束JVM的内存管理
1
JVM中的内存管理主要是指JVM对于Heap的管理,这是因为Stack,PC Register和Native Method Stack都是和线程一样的生命周期,在线程结束时自然可以被再次使用.虽然说Stack的管理不是重点,但是也不是完全不讲究的
1
2
3
4
5
6
7
8
9
10
11
12* 栈的管理
JVM允许栈的大小是固定的或者是动态变化的.Stack的设置是通过-Xss来设置其大小.
我们一般通过减少常量,参数的个数来减少栈的增长,在程序设计时,我们把一些常量定义到一个对象中,然后来引用他们可以体现这一点.另外,少用递归调用也可以减少栈的占用
栈是不需要垃圾回收的,尽管说垃圾回收是java内存管理的一个很热的话题,栈中的对象如果用垃圾回收的观点来看,他永远是live状态,是可以reachable的,所以也不需要回收,他占有的空间随着Thread的结束而释放
另外栈上有一点得注意的是,对于本地代码调用,可能会在栈中申请内存,比如C调用malloc(),而这种情况下,GC是管不着的,需要我们在程序中,手动管理栈内存,使用free()方法释放内存
关于栈一般会发生以下两种异常:
1.当线程中的计算所需要的栈超过所允许大小时,会抛出StackOverflowError
2.当Java栈试图扩展时,没有足够的存储器来实现扩展,JVM会报OutOfMemoryError1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16* 堆的管理
堆的管理要比栈管理复杂的多,我通过堆的各部分的作用,设置,以及各部分可能发生的异常,以及如何避免各部分异常
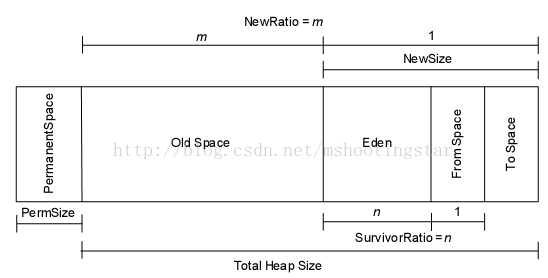
下图是Heap和PermanentSapce的组合图,其中Eden区里面存着是新生的对象,From Space和To Space中存放着是每次垃圾回收后存活下来的对象,所以每次垃圾回收后,Eden区会被清空.存活下来的对象先是放到From Space,当From Space满了之后移动到To Space.当To Space满了之后移动到Old Space.
Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor复制过来的对象.而且,Survivor区总有一个是空的.同时,根据程序需要,Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能
Old Space中则存放生命周期比较长的对象,而且有些比较大的新生对象也放在Old Space中
堆的大小通过-Xms和-Xmx来指定最小值和最大值,通过-Xmn来指定Young Generation的大小(一些老版本也用-XX:NewSize指定(即下图中的Eden加FromSpace和ToSpace的总大小)),然后通过-XX:NewRatio来指定Eden区的大小,在Xms和Xmx相等的情况下,该参数不需要设置.通过-XX:SurvivorRatio来设置Eden和一个Survivor区的比值
堆异常分为两种:
1.Out of Memory(OOM)
2.Memory Leak(ML)
Memory Leak最终将导致OOM.实际应用中表现为:从Console看,内存监控曲线一直在顶部,程序响应慢,从线程看,大部分的线程在进行GC,占用比较多的CPU,最终程序异常终止,报OOM.OOM发生的时间不定,有短的一个小时,有长的10天一个月的.
关于异常的处理,确定OOM/ML异常后,一定要注意保护现场,可以dump heap,如果没有现场则开启GCFlag收集垃圾回收日志,然后进行分析,确定问题所在.如果问题不是ML的话,一般通过增加Heap,增加物理内存来解决问题,是的话,就修改程序逻辑
- JVM垃圾回收
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40JVM中会在以下情况触发回收: 对象没有被引用,作用域发生未捕捉异常,程序正常执行完毕,程序执行了System.exit(),程序发生意外终止
JVM中标记垃圾使用的算法是一种根搜索算法.简单的说,就是从一个叫GC Roots的对象开始,向下搜索,如果一个对象不能达到GC Roots对象的时候,说明它可以被回收了.这种算法比一种叫做引用计数法的垃圾标记算法要好,因为它避免了当两个对象啊互相引用时无法被回收的现象
JVM中对于被标记为垃圾的对象进行回收时又分为了一下3种算法:
* 标记清除算法
该算法是从根集合扫描整个空间,标记存活的对象,然后在扫描整个空间对没有被标记的对象进行回收,这种算法在存活对象较多时比较高效,但会产生内存碎片
* 复制算法
该算法是从根集合扫描,并将存活的对象复制到新的空间,这种算法在存活对象少时比较高效
* 标记整理算法
标记整理算法和标记清除算法一样都会扫描并标记存活对象,在回收未标记对象的同时会整理被标记的对象,解决了内存碎片的问题
JVM中,不同的内存区域作用和性质不一样,使用的垃圾回收算法也不一样,所以JVM中又定义了几种不同的垃圾回收器:
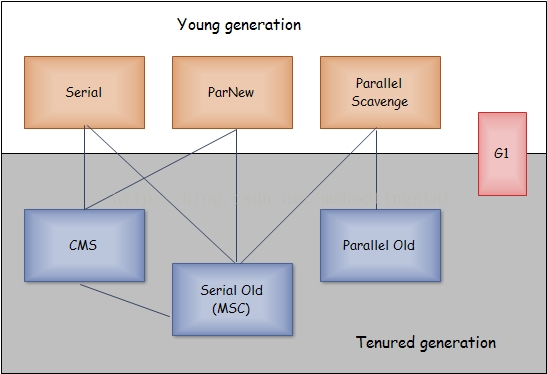
* Serial GC
从名字上看,串行GC意味着是一种单线程的,所以它要求收集的时候所有的线程暂停.这对于高性能的应用是不合理的,所以串行GC一般用于Client模式的JVM中
* ParNew GC
是在Serial GC的基础上,增加了多线程机制.但是如果机器是单CPU的,这种收集器是比Serial GC效率还低
* Parrallel Scavenge GC
这种收集器又叫吞吐量优先收集器,而吞吐量=程序运行时间/(JVM执行回收的时间+程序运行时间),假设程序运行了100分钟,JVM的垃圾回收占用1分钟,那么吞吐量就是99%.Parallel Scavenge GC由于可以提供比较不错的吞吐量,所以被作为了server模式JVM的默认配置
* ParallelOld
ParallelOld是老生代并行收集器的一种,使用了标记整理算法,是JDK1.6中引进的,在之前老生代只能使用串行回收收集器
* Serial Old
Serial Old是老生代client模式下的默认收集器,单线程执行,同时也作为CMS收集器失败后的备用收集器
* CMS
CMS又称响应时间优先回收器,使用标记清除算法.他的回收线程数为(CPU核心数+3)/4,所以当CPU核心数为2时比较高效些.CMS分为4个过程:初始标记,并发标记,重新标记,并发清除
* GarbageFirst(G1)
比较特殊的是G1回收器既可以回收Young Generation,也可以回收Tenured Generation.它是在JDK6的某个版本中才引入的,性能比较高,同时注意了吞吐量和响应时间
默认的GC种类可以通过jvm.cfg或者通过jmap dump出heap来查看,一般我们通过jstat -gcutil [pid] 1000可以查看每秒gc的大体情况,或者可以在启动参数中加入:-verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:./gc.log来记录GC日志
GC中有一种情况叫做Full GC,以下几种情况会触发Full GC也叫MajorGC:
* Tenured Space空间不足以创建打的对象或者数组,会执行FullGC,并且当FullGC之后空间如果还不够,那么会OOM:java heap space
* Permanet Generation的大小不足,存放了太多的类信息,在非CMS情况下回触发FullGC.如果之后空间还不够,会OOM:PermGen space。
* CMS GC时出现promotion failed和concurrent mode failure时,也会触发FullGC.promotion failed是在进行Minor GC时,survivor space放不下,对象只能放入旧生代,而此时旧生代也放不下造成的;concurrent mode failure是在执行CMS GC的过程中同时有对象要放入旧生代,而此时旧生代空间不足造成的
* 判断MinorGC后,要晋升到TenuredSpace的对象大小大于TenuredSpace的大小,也会触发FullGC
可以看出,当FullGC频繁发生时,一定是内存出问题了
注意: 下图中连线代表两个回收器可以同时使用